
Today and tomorrow I participate at the SAEroCon workshop: 4th Workshop on Software Architecture Erosion and Architectural Consistency. It has an interesting format where participants have to present papers instead of the authors themselves. Each paper gets 45 minutes: 15 minutes presentation, then comments by the author (5 to 10 minutes), and the remainder is for discussion. And it really works! Other workshops should take that format as well! There is a good mix of academia and industry.
Paper 1: Software Architecture Reconstruction and Compliance Checking – A Case Study. By Leo Pruijt, and Wiebe Wiersema. Presented by Metin Altinisik.
The paper studies the question: “How effective is automated architecture reconstruction?”. To answer this, they used the tool HUSACCT on a legacy system. They did both a manual reconstruction of the architecture, and an automated reconstruction. They compared the results using the MoJoFM metrics. HUSACCT has a bunch of modules and rule types supporting layers, facade and gateway patterns.
The software they analyzed is about 185 KLOC in C#, 10 years old and handles debt settlements for local governments. The system follows a classical three tier architecture. For the manual reconstruction, they used compliance checking often to validate their assumptions on the system. This resulted in an intended architecture with still some violtations. One of the nice results was that specialists regarding the intended architecture had quite some assumptions that turned out to be wrong…
The authors developed a layer reconstruction algorithm. The results are quite good: 10 of the 11 components were assigned correctly to four layers, resulting in a MoJoFM effectiveness of 85,7%. A folder with classes without namespace hampers the effectiveness of the tool. In Java there is a close connection with package and directory, in C# not. Somehow this seems to influence compliancy with the intended architecture. Is there evidence for this?
One of the challenging remaining questions the case company has, is how the system can be split into smaller units for maintainability. One of the main findings was that the presentation layer sent quite some SQL statements directly to the database, which was discovered using the HUSACCT tool.
The tool seems to be handy for medium sized software, but how can we scale up to larger software systems?
Paper 2: “Evaluating Software Architecture Erosion for PL/SQL Programs” by Metin Altınışık, Ersin Ersoy and Hasan Sözer, presented by Tobias Olsson
PL/SQL is a significant part of all enterprise applications. Procedures are packed in packages, say classes in OO. Procedures are coupled via calls, but also coupled to database tables. That gives different dependency graphs. The latter is not easily visible. The paper discusses an approach to discover the latter. The main question is: “how to find packages with low modularity?”. They extract dependencies between procedures, apply vector clustering, and count the number of unique clusters for each package. On top, they defined a new metric “Lack of Cohesion” (LCOM) for each package, that expresses whether the set of tables used by the procedures is cohesive.
They performed a case study on an older system, from 1993, with 80 packages, 643 precedures and 718 tables (1870 dependencies). Both variables under study are based on the same data. Are they telling the same thing? Based on some charts built by Tobias, some additional features come into play, for example size.
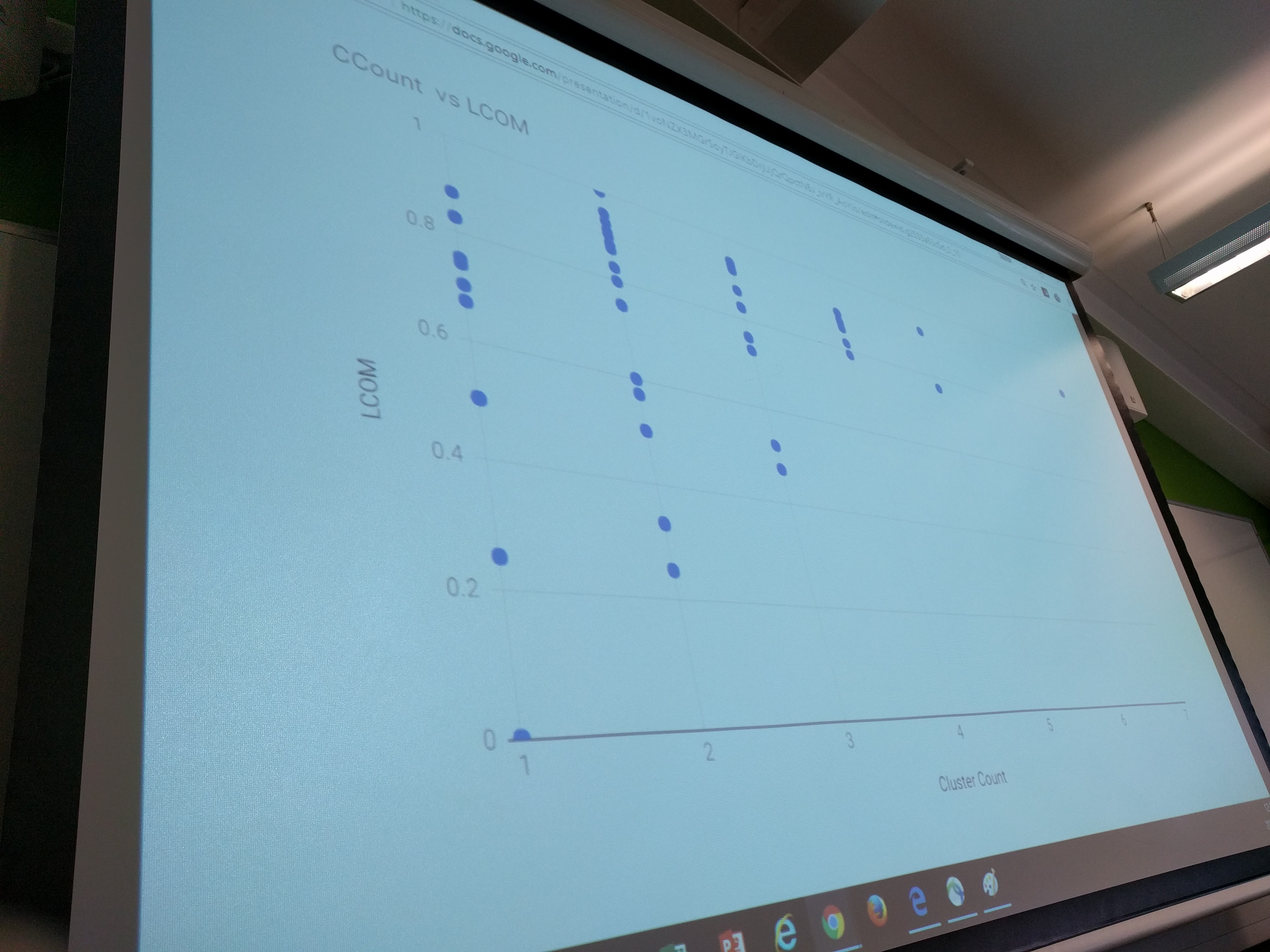

Based on his calculations, cluster count is correlated to size, but LCOM not so much. Could it be that LCOM is more a symptom of cluster count, or the other way around? How can we analyze this better?
And in general, is there any tool that allows analysis of software written in many different languages? Think nowadays of systems that use PHP, JS, SQL etc…
Paper 3: “The Relationship of Code Churn and Architectural Violations in the Open Source Software JabRef” by Tobias Olsson, Morgan Ericsson and Anna Wingkvist, presented by Jörg Lenhard
The paper presents an exploratory case study focusing on the question “What is the relation between code churn / code ownership and architectural violations?”. Code churn is the amount of added/modified/deleted LOC in a given period. Code ownership focuses on the contribution of developers. On the other hand, architecture conformance checking focues on when code breaks the architecture. The paper tries to link these concepts.


The case study explores 12 different releases, computes code churn and ownership, and computes the architectural violations using SACC, and study whether there is a link between these elements. The nice thing of Jabref is that during 2015 the team decided to develop a software architecture, and to refactor the system to this architecture. That process is still ongoing. So, they have two groups: versions pre 2015, and post 2015 with refactored files. They expected to have significant difference in code churn / code ownership in the case there is no explicit architecture. However, as the results show, there is no significant difference. Code churn in general seems to be related to architectural violations. But it is difficult to remove the effect of normal development versus refactor tasks only. Another aspect is the quality of the mapping used in the study: for the post-2015 it is much simpler to link the files / packages to the modules than for the pre 2015 versions.
Afternoon session: TEAMMATES
For the afternoon session, the organizers flew in an actual software architect of the software system TEAMMATES. The software is mainly focuses on providing feedback in courses and teams during that course. (A good candidate to replate Caracal with?). During the session, we discussed a “golden software architecture” (which is quite well documented!), and tested quite some (academic) tools. Today the focus is on the actual architecture. Tomorrow, it will be on SAR and erosion.